

深入理解CSS字符转义行为
前言
在日常的开发中,我们经常写css。比如常见的按钮:
<button class="btn"></button>,我们往往写出这样的样式
.btn {
display: inline-flex;
cursor: pointer;
user-select: none;
/* ..more decl.. */
}
然而我们有时候也会见到这样的元素:
<div class="2xl:text-base">Hello world</div>
与之对应生效的CSS样式为:
@media (min-width: 1536px) {
.\32xl\:text-base {
font-size: 1rem;
line-height: 1.5rem;
}
}
这时候就纳闷了,我明明写的是 2xl:text-base 啊?\:这个转义还好说,\3 这个又是哪来的呢?本篇文章就来从 W3C 的角度,对 css转义行为进行揭秘。
为什么要转义?
我们先把目光提升一些,其实 转义 (Escaping)这个行为,在各个语言系统中都存在,小到正则表达式,html,css,大到 javascript 或者其他成熟的编程语言,都多少存在着这种行为。
那些需要转义的字符,往往是和语言中的特定关键字(keywords/meta)产生了冲突,所以被迫让位。
比如,正则表达式中的 . 就是一个元字符,代表的是匹配任意单个除了换行符的字符。要想匹配 . 就需要转义一下写成 \.。
html 中的 <,> 需要写成 <,>,不然就会和 html 中的标签匹配方式(<div></div>)产生冲突。
而 javascript 中我们也经常写出这样的单/双引号字符串 'i\'m a "happy" fool' or "i'm a \"happy\" fool"。
同样 css 也是如此。
CSS 转义
首先让我们来看看 w3c css 转义的说明:
https://www.w3.org/TR/css-syntax-3/#escaping
Any Unicode code point can be included in an ident sequence or quoted string by escaping it. CSS escape sequences start with a backslash (\), and continue with:
- Any Unicode code point that is not a hex digits or a newline. The escape sequence is replaced by that code point.
- Or one to six hex digits, followed by an optional whitespace. The escape sequence is replaced by the Unicode code point whose value is given by the hexadecimal digits. This optional whitespace allow hexadecimal escape sequences to be followed by “real” hex digits.
从这段说明中,我们理解了转义行为具体的逻辑。大致如下图所示:
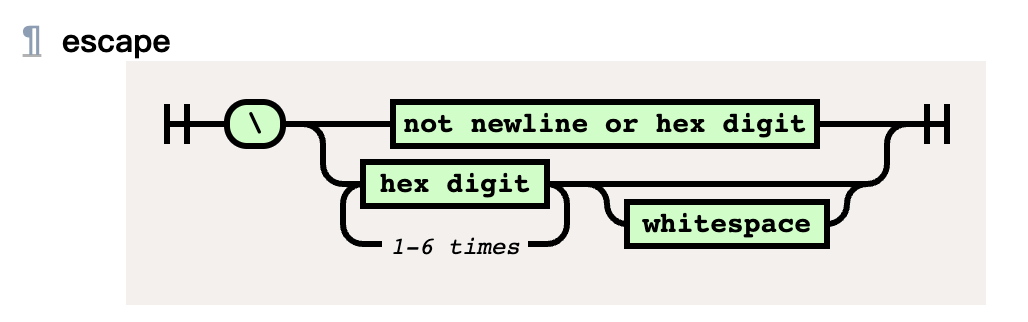
\0是一个非常特殊的字符,本篇文章不对它进行讨论,有兴趣可以自行搜索相应文档。
可以看到转义逻辑是很简单的,无非就是加 \ 判断是否是16进制数字,然后进行判断走不同的分支罢了。比如:
<div class="a:">a:</div>
我们既可以这么写,
.a\: {
color: red;
}
也可以这么写
.a\3a {
color: blue;
}
这2个选择器,效果上是等价的,但是它们各自走了不同的转义分支。
什么是合法css的表达式
这里我们以最常使用的 <ident-token> 为例,我们写的那些具体的选择器的值就需要符合这样的规范,即:
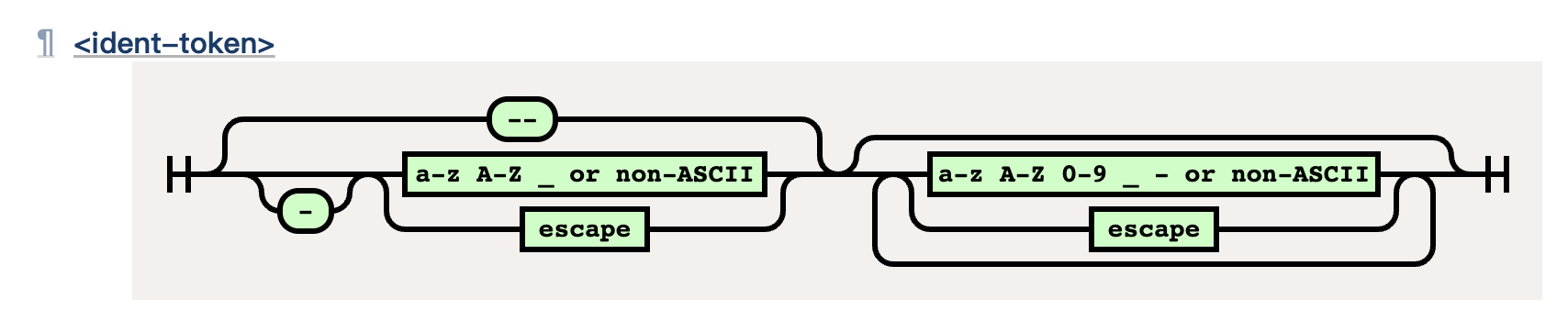
这类流程图片,相信对正则熟悉的同学,一眼就看懂了。
左半部分
我们先重点看左半部分,可以看到表达式开头必须以 -- 或 -,或者 _, a-z,A-Z,non-ASCII 开头。
这里解释一下什么是 non-ASCII,本质上就是非ASCII字符,也就是 code point > 127 的字符。
接着让我们来看看熟悉可爱的 ASCII 表吧。
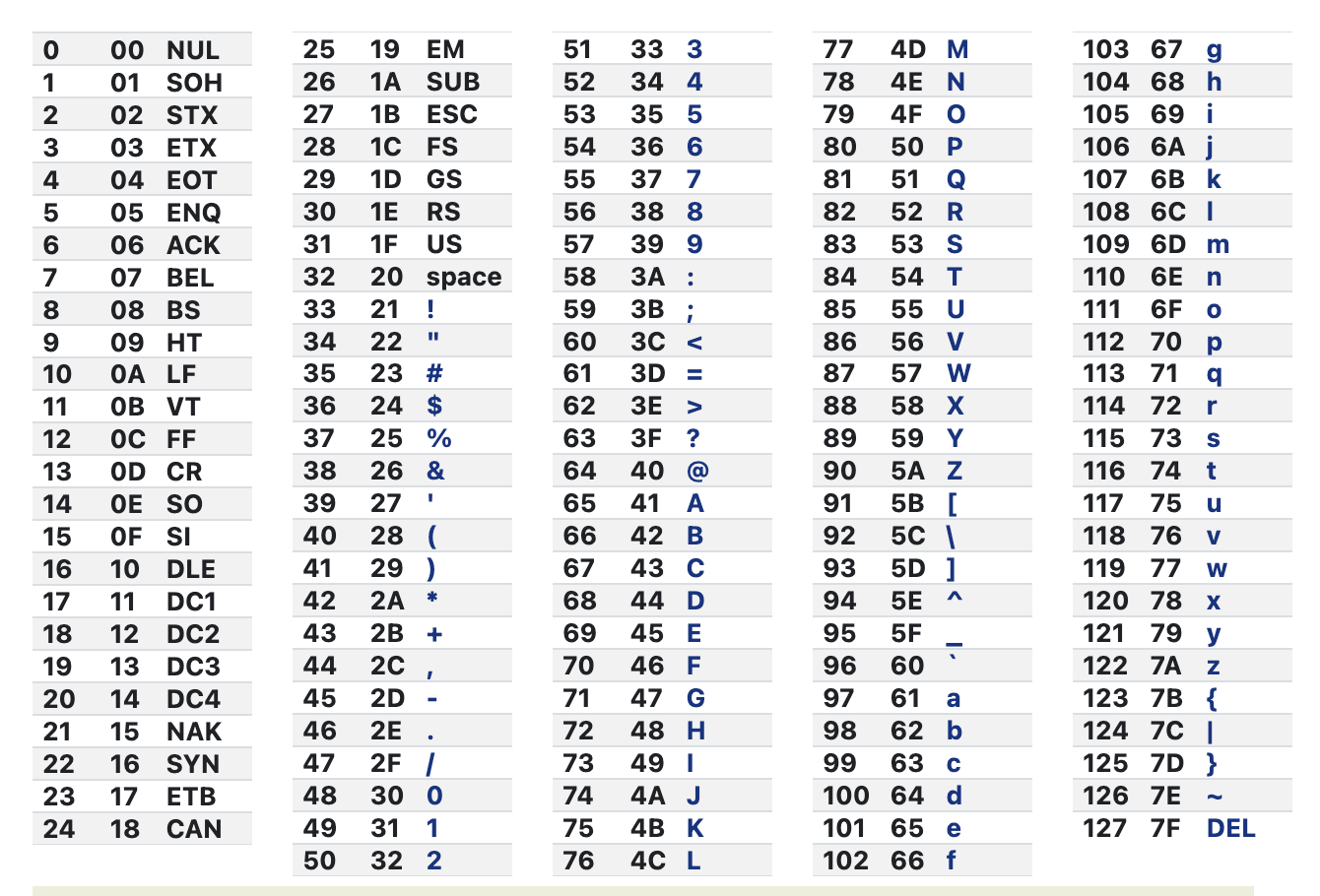
经过对照之后,可以筛选出表达式第一个字母的 code point 需要满足的要求是:
code === 45 || // -
code === 95 || // _
(code >= 97 && code <= 122) || // a-z
(code >=65 && code<=90) || // A-Z
code > 127 || // non-ASCII
(escape chars) // 或者转义字符
所以根据这个规则,所有不在上述范围内的 ASCII 字符都需要转义,才能正确表达。注意上面的表达式是不包括数字的哟,所以数字开头的类名,在写 css 选择器的时候都要进行转义,不论正负值。比如
<div class="2">2</div>
要想写选择器作用在这些元素上,就需要这样写:
.\32 {
color: red;
}
所以你就了解为什么选择 class="2" 的这个 css 选择器是 .\32 了,因为这本质上是一个 十六进制(hex) 的字符。\32 换算一下就是 3 * 16 + 2 = 50,而 50 这个 code point 在 ASCII 表里对应的字符就是 2 !
让我们再来点进阶的例子:
<div class="2b">2b</div>
<div class="2g">2g</div>
<div class="-2g">-2g</div>
对应匹配的 css 选择器为(注意注释):
/* 补全6位,不需要跟空格*/
.\000032b {
color: blue;
}
/* 没有补全6位,需要跟空格*/
.\32 b {
color: red;
}
/* 没有补全6位,然而16进制表示的字符范围是 0-f,
而字符g已经超出这个范围,所以空格 可加可不加,
而上面的 .\32 b 必须加空格,不然会认为 \32b 是一个hex数字整体 */
.\32g {
color: red;
}
/* 负数开头,即第一位是'-',第二位是数字的也需要转义 */
.-\32 g {
color: red;
}
右半部分
接下来我们来观察表达式的右半部分。
再定义完成前置部分之后,右侧不止可以接受 _,a-z,A-Z,non-ASCII,也可以接受 0-9,- 这些字符了。用代码来表达则为:
code === 45 || // -
code === 95 || // _
(code >= 48 && code <= 57) || // 0-9
(code >= 97 && code <= 122) || // a-z
(code >=65 && code<=90) || // A-Z
code > 127 || // non-ASCII
(escape chars) // 或者转义字符
相比左半部分要宽泛一些。这里我给出一些示例:
<div class="a:b">a:b</div>
<div class="lg:[&:nth-child(3)]:hover:underline"></div>
<div class="bg-[url('/img/hero-pattern.svg')]">
<!-- ... -->
</div>
<div class="text-[color:var(--my-var)]">...</div>
<div class="before:content-['我爱中国\_icebreaker']">
<!-- ... -->
</div>
与之对应的那些样式:
/*
语法错误
: 字符是 ASCII 且不在合法范围内
需要转义为 \:
*/
.a:b{
color: red;
}
/* 合法表达式 */
@media (min-width: 1024px) {
.lg\:\[\&\:nth-child\(3\)\]\:hover\:underline:hover:nth-child(3) {
text-decoration-line: underline;
}
}
.bg-\[url\(\'\/img\/hero-pattern\.svg\'\)\] {
background-image: url(/img/hero-pattern.svg);
}
.text-\[color\:var\(--my-var\)\] {
color: var(--my-var);
}
.before\:content-\[\'\6211\7231\4F60_\4E2D\56FD\\_icebreaker\'\]::before {
content: '我爱你 中国_icebreaker';
}
练习
假如你已经理解了上述内容,可以试试为下方的元素添加对应的生效的样式:
<div class="-">单个-是特殊情况哟</div>
<div class="我❤️中国,你好,世界。">我❤️中国,你好,世界。</div>
<div class="émotion">émotion</div>
<div class="-3:2yo:ur[x'\ds]">-3:2yo:ur[x'\ds]</div>
