
聚合是云开发 CloudBase 数据库中非常重要的一种数据批处理操作方式。聚合操作可以将数据分组(或者不分组,即只有一组/每个记录都是一组),然后对每组数据执行多种批处理操作,最后返回结果。
有了聚合能力,可以方便的解决很多没有聚合能力时无法实现或只能低效实现的场景,包括分组查询、只取某些字段的统计值或变换值返回、流水线式分阶段批处理、获取唯一值(去重)等。
本文就以一个简单的实例解释如何在云数据库中,实现十分常用的联表+聚合查询操作。
场景说明
假设数据库内存在两个集合:class 与 student,存在以下数据:
class(班级信息):
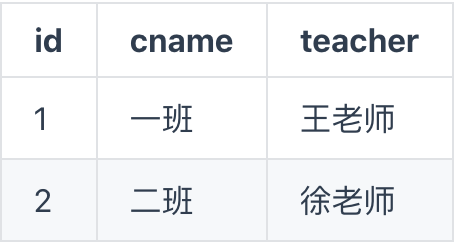
student(学生信息):
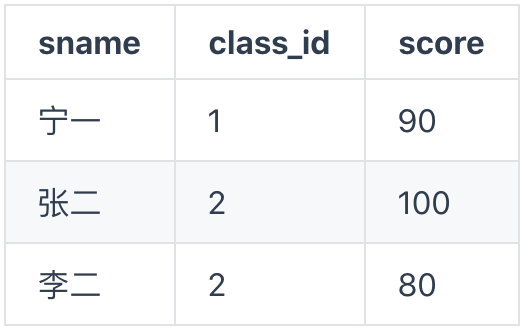
现在需要查询徐老师所带的班级里面所有学生的平均成绩。
代码示例
1、lookup 联表查询
首先我们需要把 student 内的所有数据,按照 class_id 进行分组,这里我们使用云数据库的 lookup 操作符:
lookup({
from: "student", //要关联的表student
localField: "id", //class表中的关联字段
foreignField: "class_id", //student表中关联字段
as: "stu" //定义输出数组的别名
}).end();
这个语句会查出来下面的结果,会查出班级的信息以及该班级所对应的所有学生的信息:
{"list":
[{
"id":1,
"teacher":"王老师",
"cname":"一班",
"stu":[
{
"sname":"宁一",
"class_id":1,
"score":90
}
]
},
{
"id":2,
"teacher":"徐老师",
"cname":"二班",
"stu":[
{
"class_id":2,
"sname":"张二",
"score":100
},
{
"class_id":2,
"sname":"李二",
"score":80
}
]
}]
}
但是我们只需要徐老师所在班级学生的数据,所以需要进一步过滤。
2、match 条件匹配
现在就只是返回徐老师所在班级的学生数据了,学生数据在 stu 对应的数组里面:
.lookup({
from: 'student',
localField: 'id',
foreignField: 'class_id',
as: 'stu'
})
.match({
teacher:"徐老师"
})
.end()
现在就只是返回徐老师所在班级的学生数据了,学生数据在 stu 对应的数组里面:
{
"list": [
{
"_id": "5e847ab25eb9428600a512352fa6c7c4",
"id": 2,
"teacher": "徐老师",
"cname": "二班",
//学生数据
"stu": [
{ "_id": "37e26adb5eb945a70084351e57f6d717", "class_id": 2, "sname": "张二", "score": 100 },
{ "_id": "5e847ab25eb945cf00a5884204297ed8", "class_id": 2, "sname": "李二", "score": 80 }
]
}
]
}
接下来我们继续优化代码,直接返回学生的平均分数。
3、直接返回学生成绩平均值
如果想要在被连接的表格中(本课程中的 student)做聚合操作,就用 pipeline 方法:
.lookup({
from: 'student',
pipeline: $.pipeline()
.group({
_id: null,
score: $.avg('$score')
})
.done(),
as: 'stu'
})
.match({
teacher:"徐老师"
})
.end()
现在输出的数据是这样的:
{
"list": [
{
"_id": "5e847ab25eb9428600a512352fa6c7c4",
"id": 2,
"teacher": "徐老师",
"cname": "二班",
"stu": [{ "_id": null, "score": 90 }]
}
]
}
但是现在输出的数据有点复杂,如果只想显示 teacher 和 score 这两个值,我们再进行下面的操作。
4. 只显示 teacher 和 score 这两个值
我们使用 replaceRoot、mergeObjects 和 project 进行最后的处理:
.lookup({
from: 'student',
pipeline: $.pipeline()
.group({
_id: null,
score: $.avg('$score')
})
.done(),
as: 'stu'
})
.match({
teacher:"徐老师"
})
.replaceRoot({
newRoot: $.mergeObjects([$.arrayElemAt(['$stu', 0]), '$$ROOT'])
})
.project({
_id:0,
teacher:1,
score:1
})
.end()
现在输出的数据是这样的:
{ "list": [{ "score": 90, "teacher": "徐老师" }] }
相关文档:云开发聚合搜索:https://docs.cloudbase.net/database/aggregate.html
产品介绍
云开发(Tencent CloudBase,TCB)是腾讯云提供的云原生一体化开发环境和工具平台,为开发者提供高可用、自动弹性扩缩的后端云服务,包含计算、存储、托管等serverless化能力,可用于云端一体化开发多种端应用(小程序,公众号,Web 应用,Flutter 客户端等),帮助开发者统一构建和管理后端服务和云资源,避免了应用开发过程中繁琐的服务器搭建及运维,开发者可以专注于业务逻辑的实现,开发门槛更低,效率更高。
开通云开发:https://console.cloud.tencent.com/tcb?tdl_anchor=techsite
产品文档:https://cloud.tencent.com/product/tcb?from=12763
技术文档:https://cloudbase.net?from=10004
技术交流加Q群:601134960
最新资讯关注微信公众号【腾讯云云开发】

例行点赞
想问问三个表的例子,A表和B表有关联的字段(如A表id关联B表的a_id),B表和C表有另一个关联字段(如B表id关联C表的b_id),怎样同时关联查询A、B、C表?
from: "C",
localField: "B.id",
foreignField: "b_id",
as: "C"
}
如果多个表都有同一名称字段,比如都有 teacher 这个字段,那么 match里面怎么区分?
解决我的问题拉
OK,收藏了,晚上回去慢慢学习!
猫宁一