# 最佳实践
为了达到更好的用户体验,我们提供了一些最佳实践,从产品设计和 SKILL 封装两个方面展开。
# 一、产品设计
以下以 WeStoreCafe 点单 SKILL 为参考案例,梳理此模式下的核心设计点:
对话承接用户的模糊意图:当用户表达"想喝点清爽的""最近有什么推荐"这类非结构化需求时,由 AI 完成理解和推荐,再引导至原子组件完成确认和下单。
可通过自然语言修改内容:用户无需跳出对话,可直接对话修改如规格、时间、地点等枚举值或明确实体的字段内容。
历史数据与个人资产可查询、可操作:高频消费场景下的核心诉求是效率,"再来一杯上次喝的""用积分兑换一张优惠券"这类指令可被执行,能提升使用效率。
服务进程动态实时更新:订单或服务原子组件随状态推进动态更新,而非静态展示,防止用户错过关键更新。
# 二、SKILL 封装
# 1、信息源与分工
小程序 AI 在决定调用哪个原子接口、生成什么参数、回复什么内容时,会综合多个上下文信息源做判断。这些信息源在权重和职责上各有侧重,写在错误的位置会显著降低准确率。
# 1.1 注意力权重
| 信息源 | 注意力 | 说明 |
|---|---|---|
原子接口返回的 content | ★★★★★ | 离当前决策点最近,模型会把它当作“事实 + 动作”读取(参见 4.2)。这里出现错误话术,会让模型偏离 SKILL.md 的约定 |
原子接口声明(mcp.json)里的 description | ★★★★ | 影响模型“选不选这个接口”,写得模糊时模型容易选错 |
原子接口声明(mcp.json)里的 inputSchema.description | ★★★★ | 影响模型“怎么填参数”,是字段级约束的核心位置,比写在 SKILL.md 长文里更有效 |
SKILL.md | ★★★ | 适合写业务流程编排、跨接口规则、意图分流、通用规范 |
# 1.2 内容分工
| 信息源 | 写什么 |
|---|---|
原子接口返回的 content | 本次调用结果与下一步动作 |
原子接口声明里的 description | 接口本身的功能、调用时机、不适用场景 |
原子接口声明里的 inputSchema.description | 参数语义、取值来源、缺省处理 |
SKILL.md | 业务流程编排、跨接口规则、意图分流、通用规范 |
# 1.3 常见错位
- 把“接口本身的功能”写到
SKILL.md:长文膨胀、与mcp.json易不一致。SKILL.md中的接口清单只写“前置条件 + 上下游关系”。 - 把“跨多接口的业务规则”写到单个接口的
description:仅在调用该接口时生效,其他接口决策时模型读不到。应写在SKILL.md。 - 把“接口功能描述”写到
content:content只承载本次调用结果与下一步动作,功能描述属于description。
# 2、通用写作原则
适用于上述所有信息源。
- 同一约束在一处书写。重复书写容易因措辞不一致引发冲突。
- 硬约束放在权重更高的位置。能在代码层面基于规则强校验的约束,优先做代码校验。
- 给出可执行出口。只写“不要做 X”而不写“应做什么”,模型会缺少出口。每条禁令都应配一个明确的替代动作。
# 3、原子接口声明(mcp.json)
# 3.1 接口 description
- 接口名使用语义化名称。推荐采用「动词+名词」的小驼峰命名,例如
searchDrinks优于search,语义更明确。 - 首句声明「业务对象」,而非「入参」。
- 反例:“按关键词、温度、杯型搜索商品列表(仅饮品)……” —— 首句强调入参,且“商品”语义过宽,模型可能误命中其他商品类目。
- 推荐:“搜索饮品。按关键词、温度、杯型检索……” —— 首句先点明业务对象,再描述入参维度。
- 不写内部实现细节。实现具体细节对模型选择接口没有帮助,会挤占真正重要的“使用边界”信息。
- 职责单一,描述互不重叠。接口之间避免包含关系;描述面向模型而非用户,措辞简洁即可。
- 同名字段统一命名。同一含义的字段在不同接口保持一致,例如饮品 ID 始终用
drinkId,不要混用itemId。
# 3.2 字段 description
入参字段选取:优先传 ID 而非自然语言,例如门店传 storeId 而非省市街道,饮品传 drinkId 而非饮品名称、类目。模型不必再从自然语言中反复提取和匹配,参数歧义更少,推理也更快、更稳。
description 书写:以下给出两类典型字段的写法示例。
普通字段:举例时给多个不同样本(避免被当默认值),并配明确的缺省处理。单一举例容易被模型当作"标准答案"——用户只说“想喝点什么”时,可能直接照搬该例子填入。
// 反例:只举一个例子,且未说明缺省处理
"keyword": { "description": "饮品关键词,如『拿铁』" }
// 推荐:多样化举例 + 缺省处理
"keyword": {
"description": "饮品关键词,例如『拿铁』『美式』『奶茶』。用户未说出具体饮品时,不要填写本字段,应改走饮品推荐接口。"
}
ID 类字段:声明取值来源接口。业务 ID 容易被按格式凑出,需在 description 中显式声明来源。
// 反例
"drinkId": { "description": "饮品 ID" }
// 推荐
"drinkId": {
"description": "饮品唯一标识,取自上游接口 searchDrinks 或 getRecommendedDrinks 返回的 drinkId 原值。不要从用户自然语言(如『那个拿铁』)推断,也不要使用示例值。上下文无可用 drinkId 时,应先调 searchDrinks。"
}
# 4、原子接口返回 content
content 直接面向小程序 AI,承载本次调用结果并约束下一步动作。
# 4.1 通用规则
输入校验
- 小程序 AI 生成的参数不保证正确,原子接口需校验类型与有效性(如
drinkId是否存在)。
返回内容
structuredContent与content都会提供给小程序 AI:前者承载结构化数据(卡片展示内容),后者承载结果说明与决策约束,两者避免重复。- 渲染需要但小程序 AI 无需理解的内容(如图片地址、后台冗余字段)通过
_meta传递。
错误处理
- 返回明确的错误原因与下一步指引:
- 缺信息:“缺少收货地址,需用户补充”;
- 无结果:“未找到相关饮品,可换关键词重试”。
# 4.2 事实 + 动作两段式
content 应先陈述本次返回的客观状态,再给出下一步动作。仅有动作没有事实时,模型可能把"展示卡片"理解为"准备调下一步接口"而跳过等待用户确认。
// 反例:仅给动作,缺少事实
"接下来请务必为用户展示订单确认卡片。"
// 推荐:事实 + 动作
"已根据所选规格生成订单。请展示订单确认卡片,并用一句话引导用户核对后下单。"
# 4.3 失败 / 空结果
失败或空结果分支的 content 应包含三件事:
- 陈述具体事实:把问题原因写清楚,如未在饮品库中匹配到名为「圣诞限定款」的饮品;
- 给出下一步出口:接下来应该 xxx;
- 指出不应做的动作:如禁止再重复尝试调用此原子接口。该条须与第 2 条配对出现,不要只写禁令而不给出口。
示例:
- 未匹配到「圣诞限定款」,已附带「本店热销饮品」兜底数据。
- 请先告诉用户“未找到「圣诞限定款」”,并引导用户在以下本店热销饮品中挑选。
- 不要再以相同关键词重复调用本接口。
# 5、SKILL.md
mcp.json 描述“单个接口怎么用”,SKILL.md 描述“整个业务怎么跑”:业务流程、接口依赖、跨接口约束。
# 5.1 业务流程
把“用户意图 → 原子接口 → 用户操作 → 原子接口”梳理清楚,便于模型理解整体编排。书写要点:
- 节点用接口名,接口名与
mcp.json的原子接口完全一致(含大小写); - 从用户意图入口分支,每个分支对应一类典型表达(模糊 / 明确关键词 / 特定场景);
- 标注用户操作节点(如“用户选择某款”“用户确认”),用以区分由谁触发下一步;
- 标注分支,对“无 X 时先走兜底接口、补全后回到主流程”这类场景。
# 5.2 接口依赖关系
业务流程描述整体走向,依赖关系表则按接口维度列出触发前置条件,便于模型在调用前快速判断当前是否满足条件。
# 5.3 业务约束
跨多个接口生效的强约束写在 SKILL.md,常见类型:
- 输出形态:何时必须出卡片、何时才能出纯文本;
- 执行顺序:动作类接口必须确认原子接口执行成功,未调用前不应向用户宣称“已为您完成”;
- 并发串行:如订单支付原子接口不应并发,须等上一笔结束(成功、失败或取消)后再发起;
- 数据来源:业务 ID 应取自上游接口的真实返回,不要从用户语言推断或编造。
# 6、上行消息文案撰写建议
用户在原子卡片及半屏进行操作,有时会自动上行一条消息至对话区。这条消息将直接展示给C端用户,本质上是系统代替用户发出的一条对话内容,需要避免表达不自然、系统感强等问题。
# 6.1 基本原则
- 用户视角出发:文案应以用户口吻表达,让用户看到后不会产生系统在替我说话的感受。
- 操作语义准确:文案应准确反映用户刚刚完成的实际操作,不扩大、不缩减、不歪曲用户意图。
- 会话承接自然:文案进入对话流后,应能被后续服务自然承接,不造成语义突兀或流程割裂。
- 对话简洁清晰:文案应避免系统播报感、技术描述感和字段拼接感,控制信息量,减少对会话阅读体验的干扰。
# 6.2 具体撰写原则
| 原则 | 说明 | 示例 |
|---|---|---|
| 用户视角出发 | 消息需站在用户视角表述,可使用第一人称,一般不建议使用其他人称 |  |
| 不可上行系统消息 | 即使是用户操作导致的异常系统消息,也不可以上行,需要转换成用户操作 |  |
| 自然语言表达 | 用自然语言表达,摒弃字段罗列、编码等技术性描述格式 |  |
| 使用生活化语言 | 表意准确基础上,优先选用生活化口语,规避专业性过强的术语 |  |
| 仅限用户已明确表达的信息 | 信息仅限用户当前操作可推导内容,不可擅自补充用户未说明的偏好或诉求 |  |
| 描述当前操作 | 描述聚焦当下操作,不能描述其他环节或提前预判未来操作 | 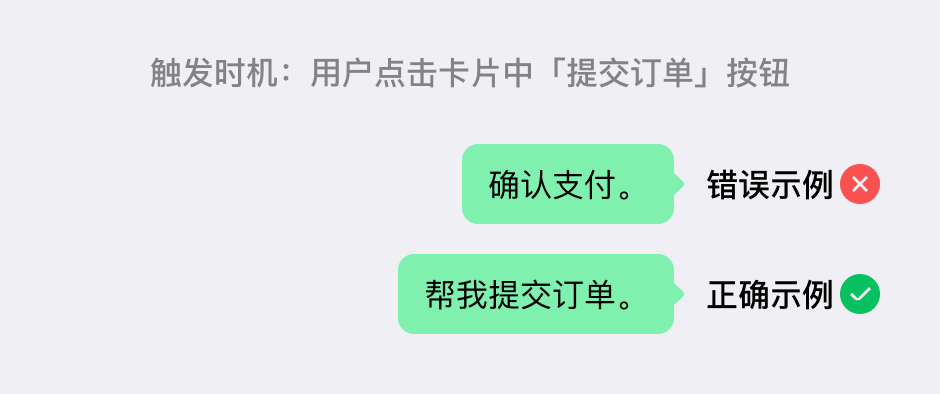 |
| 信息充分但不过载 | 只保留能推动当前对话或有助于模型理解的必备信息,次要信息可以不说明 |  |
| 简洁但不歧义 | 精简文案长度的同时保证表意清晰,尤其多选择场景下规避这个、那个等指代模糊的用词 |  |
| 处理敏感信息 | 身份证号、手机号等隐私信息禁止明文展示,必要时脱敏模糊表述 |  |
| 其他通用性文案规范 | 无错别字,无病句,正确断句,正确使用空格、标点符号等 |  |
 文档变更日志(2条)
文档变更日志(2条)