# 配置信息
例如:
APPID: xxxxxxxxxxxxxxx
TOKEN: xxxxxxxxxxxxxxx
EncodingAESKey: xxxxxxxxxxxxxxx
# 接口信息
句子相似度计算以及排序。
输入一个参考句和若干个候选句子,本服务可以计算每个候选和参考句之间的语意相似度,并按照相似度降序排列候选句子。
# 句子相似度计算接口(只签名不加密):
https://chatbot.weixin.qq.com/openapi/nlp/rank/TOKEN
接口类型:
POST请求
# 参数说明:
| 字段 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| query | string | 使用JWT签名后的数据 |
query签名说明:
| 字段 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| uid | string | 自动生成的随机标识 | 用户标识的唯一ID,比如:openid |
| data | Object | {query: "输入文本", candidates: [{"text": "待对比候选"}, {"text": "包含1个或多个句子"}]} |
使用JSON Web Token的 HS256 算法对参数进行encode, 放入到query参数中
比如参数为
{
uid: "xjlsj33lasfaf", //能标识用户的唯一用户id,可以是openid
data: {
query: "北京到上海的火车票",
candidates: [
{text: "上海到北京的火车票"},
{text: "北京到上海的飞机票"},
{text: "北京到上海的高铁票"}
]
}
}
使用 jwt 和 EncodingAESKey 对数据对象进行encode得到加密字符串
const signedData = jwths256.encode(EncodingAESKey, {
uid: "xjlsj33lasfaf", //能标识用户的唯一用户id,可以是openid
data: {
query: "北京到上海的火车票",
candidates: [
{text: "上海到北京的火车票"},
{text: "北京到上海的飞机票"},
{text: "北京到上海的高铁票"}
]
}
}
)
# 调用开放平台语义接口
curl -XPOST -d "query=signedData" https://chatbot.weixin.qq.com/openapi/nlp/rank/TOKEN
Tips: 在 jsonwebtoken.io 网站上可以参考如下步骤手动生成signedData
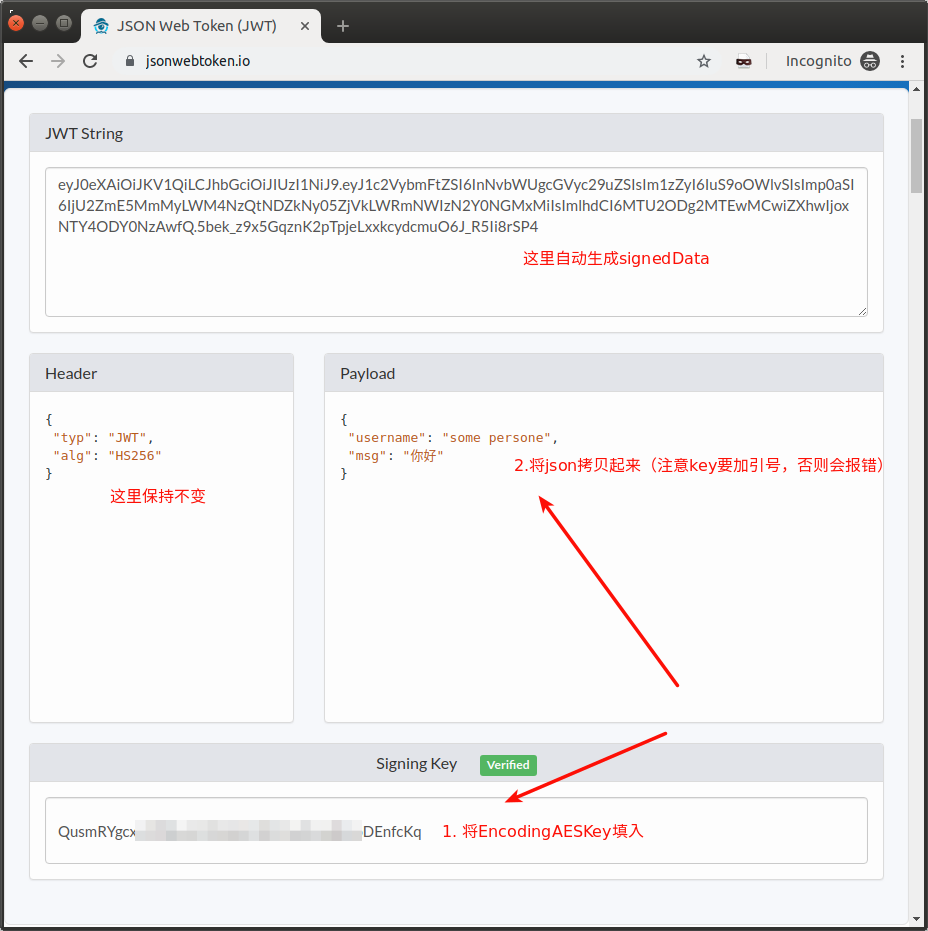
# 返回结果
| 名称 | 类型 | 说明 |
|---|---|---|
| results | list | 每个候选的相似度打分,按照打分降序排列 |
| exact_match | bool | 是否有exact match的候选 |
示例:
{
"error": "",
"results": [
{
"question": "北京到上海的高铁票",
"score": 0.9875847458814624
},
{
"question": "北京到上海的飞机票",
"score": 0.9707289708500416
},
{
"question": "上海到北京的火车票",
"score": 0.9169014875286918
}
],
"exact_match": false
}