# 词典
词典是一个规范的自然语言短语集合,通常定义为应用所在领域的术语的集合,可用于用户说法中的关键信息提取和语义槽调用。词典可被多个技能重复引用,用于提升用户输入解析的准确性与一致性。 例如:
- "刮风 / 降雨"属于「天气」词典
- "跑步 / 游泳"属于「运动」词典
# 系统词典
统词典以 sys.为标识,是平台为开发者预置的词典,可直接在技能中引用,不支持新增、删除或编辑。每个系统词典内已包含丰富的词条,平台提供了词条示例,便于开发者理解系统词典含义。
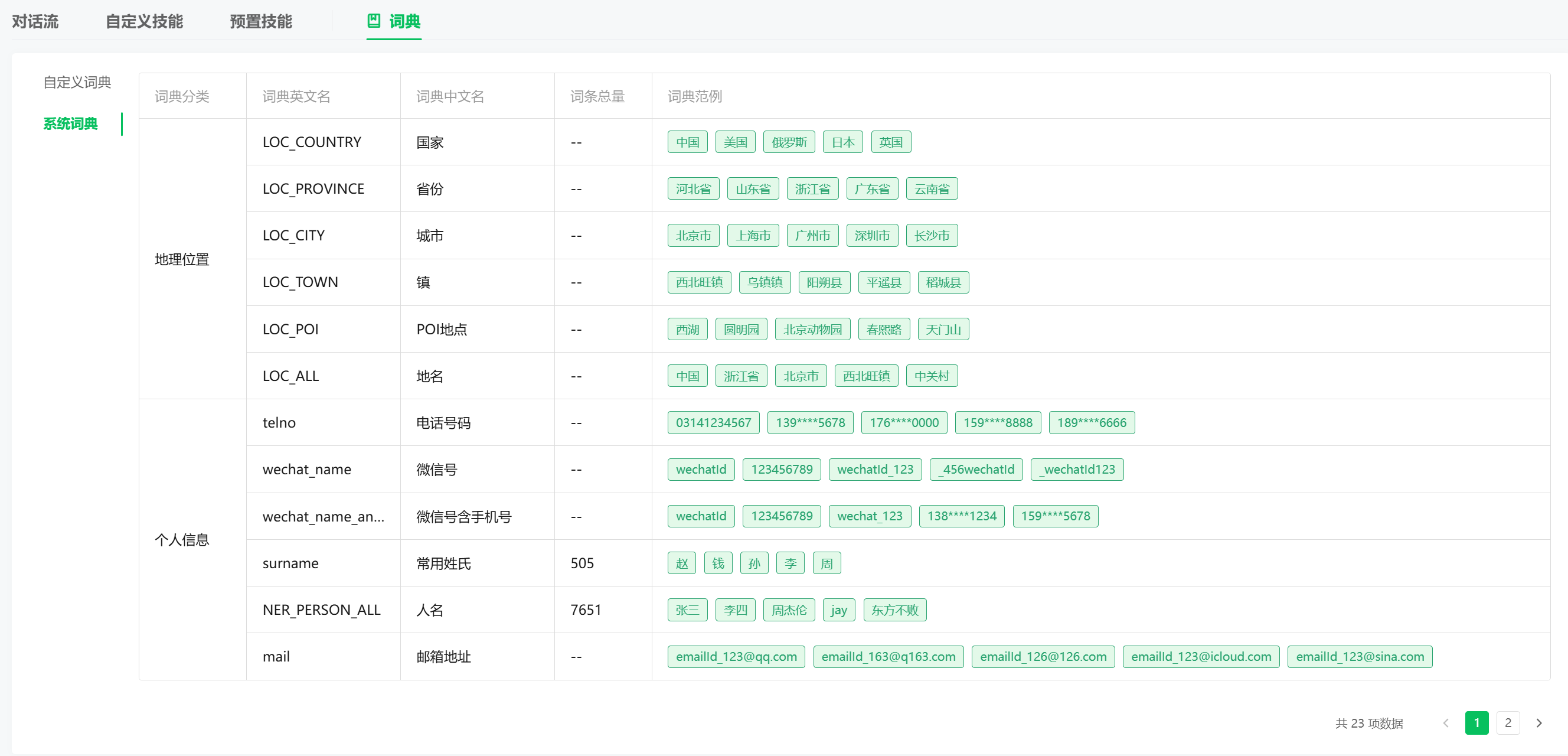
# 系统词典说明
注:系统词典不可修改,只能引用
| 符号样式 | 词典简介 | 举例 |
|---|---|---|
| sys.国家 | 国家名称词典,需要关键词存在国家名称才可以触发 | 中国 |
| sys.省份 | 省份名称词典,需要关键词存在省份名称才可以触发 | 浙江省 |
| sys.城市 | 城市名称词典,需要关键词存在城市名称才可以触发 | 北京,上海 |
| sys.镇 | 镇名称词典,需要关键词存在镇名称才可以触发 | 不老屯镇 |
| sys.POI地点 | 地点名称词典,需要关键词存在地点名称才可以触发 | 西湖 |
| sys.地名 | 地名名称词典,需要关键词存在"任何"地名名称均可以触发 | 包含国家/城市/省/镇/小地名 |
| sys.重复时间点 | 时间词典,需要关键词存在时间信息才可以触发(具体实用结合实例) | 每天下午3点 |
| sys.具体时间点 | 时间词典,需要关键词存在时间信息才可以触发(具体实用结合实例) | 今天下午3点 |
| sys.时间区间 | 时间词典,需要关键词存在时间信息才可以触发(具体实用结合实例) | 今天下午三点到明天上午6点 |
| sys.一段时间 | 时间词典,需要关键词存在时间信息才可以触发(具体实用结合实例) | 3小时25分钟 |
| sys.所有时间说法 | 时间词典,需要关键词存在"任何"时间信息都可以触发 | 每天下午3点,今天下午3点,今天下午三点到明 |
| sys.任何数字 | 数字词典,任何数字均可触发 | 20,-11.3%,一百五 |
| sys.价格 | 价格词典,需要关键词存在价格信息可以触发 | |
| sys.人名 | 姓名词典,需要关键词存在人名才可以触发 | 张小龙,王小明 |
| sys.邮箱地址 | 邮箱词典,需要关键词存在邮箱地址才可以触发 | hello@wechat.com |
| sys.电话号码 | 电话词典,需要关键词存在电话号码才可以触发 | 13888888888 |
| sys.常用姓氏 | 姓氏词典,需要关键词存在姓氏才可以触发 | 用户返回常用姓氏 |
| sys.微信号 | 微信号词典,需要关键词存在微信号才可以触发 | 用于返回微信账号 |
| sys.微信号含手机号 | 微信号词典,需要关键词微信号或手机号可以触发 | 用于返回微信号及手机号 |
| sys.普通网址 | 需要关键词存在网址才可以触发 | www.wechat.com |
| sys.IP地址 | IP地址词典,需要关键词存在IP地址才可以触发 | 10.1.1.1 |
| sys.IP转地址 | IP地址词典,调用者IP转地址 | 10.1.1.1 |
| sys.任意说法 | 特殊词典,任何问题均可触发的词典,也可以提取信息使用 | 用于匹配用户Query |
# 自定义词典
如果系统词典不能满足技能开发需要,开发者还可以创建自定义词典,自定义词典以 user.为标识,开发者可根据需要对词典与词条的增删改和同义词与权重配置。
- 建步骤:【配置】→【任务技能】→【词典】→【自定义词典】→【新增词典】,填写词典中英文名称后即可创建。
# 词条管理
新增词条:自定义词典创建成功后点击【新增一条】就可添加词条
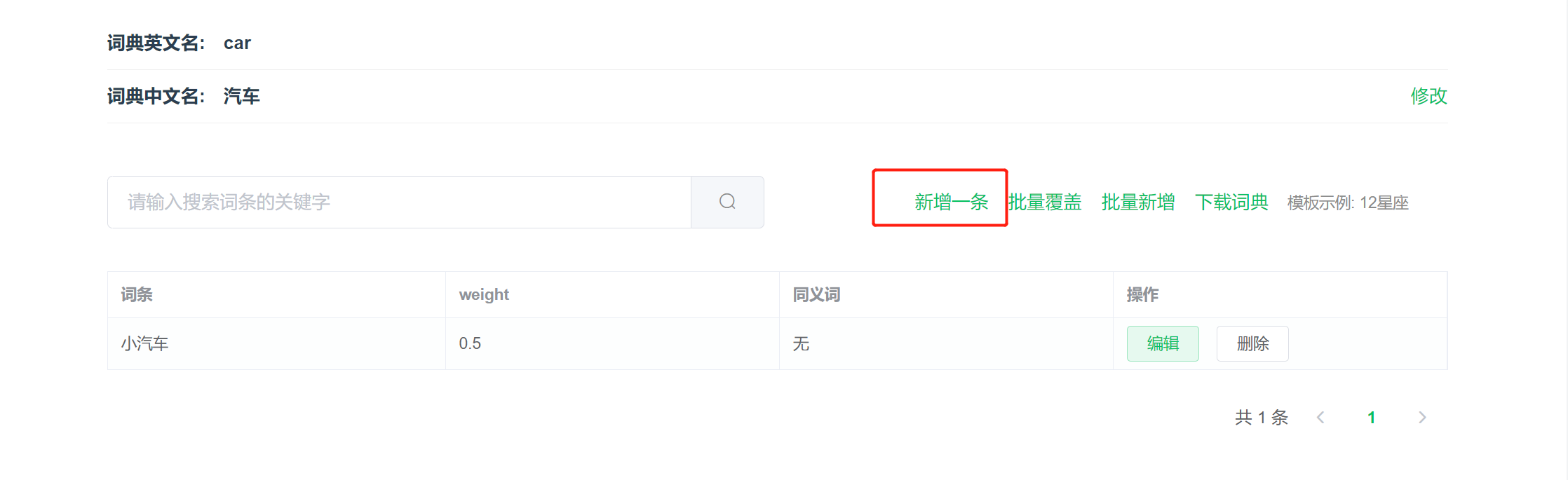
编辑/删除词条:词条添加成功后,点击词条右侧【编辑/删除词条】即可修改词条
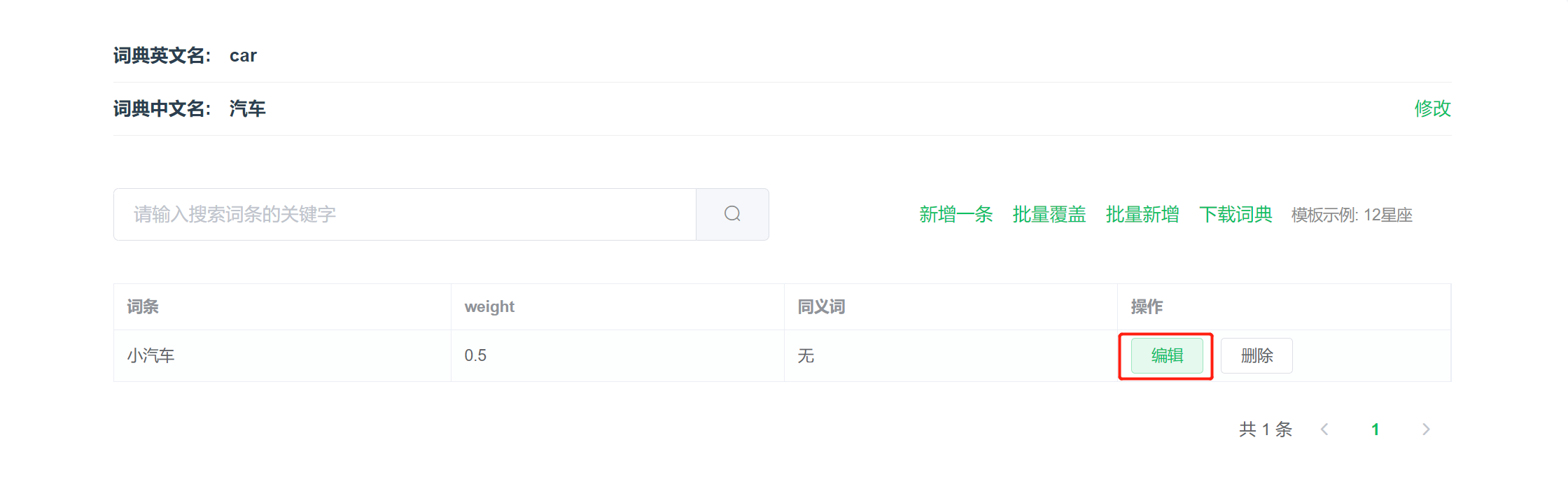
词条同义词:词条的编辑支持添加同义词(可添加多条),用于提升匹配召回
词条weight:默认 0.5,权重越高,词条在匹配用户输入时被触发的优先级越高

# 词典-词条批量导入
为方便用户管理自定义词典,平台支持对词典中的词条进行批量上传,包含【批量上传】及【批量覆盖】两种方式。如果用户想更新已经上传过的自定义词典内容,推荐使用【批量覆盖】的方式上传
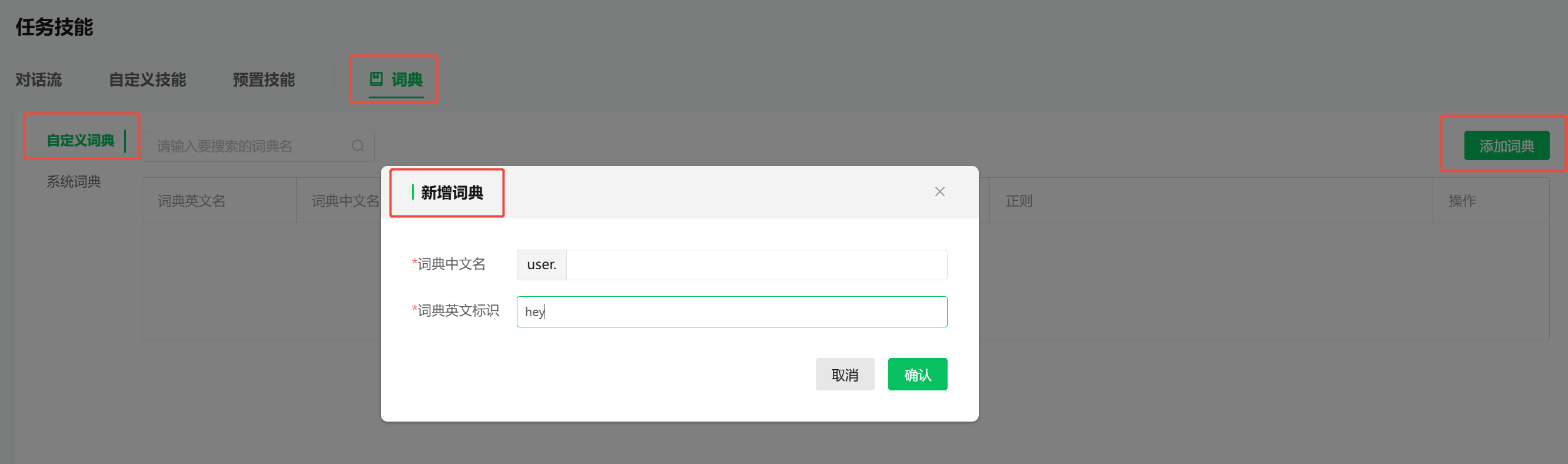
第一步 新建词典
在【配置】-【任务技能】-【词典】-【自定义词典】-【新增词典】
第二步 按照使用要求准备数据
csv文件,可用Excel表格工具或文本编辑器打开
| 表头名称 | 名词解释 | 填写说明 |
|---|---|---|
| 词条名 | 对应词典中的词条名 | 直接填写 |
| 同义词 | 同义词 | 直接填写,非必填。允许上传多个,可用";"隔开。也可以后续允许在平台上补充 |
第三步 上传词典数据
在新增词典的【操作】菜单下【修改图标】中的【修改词条】进入词条编辑
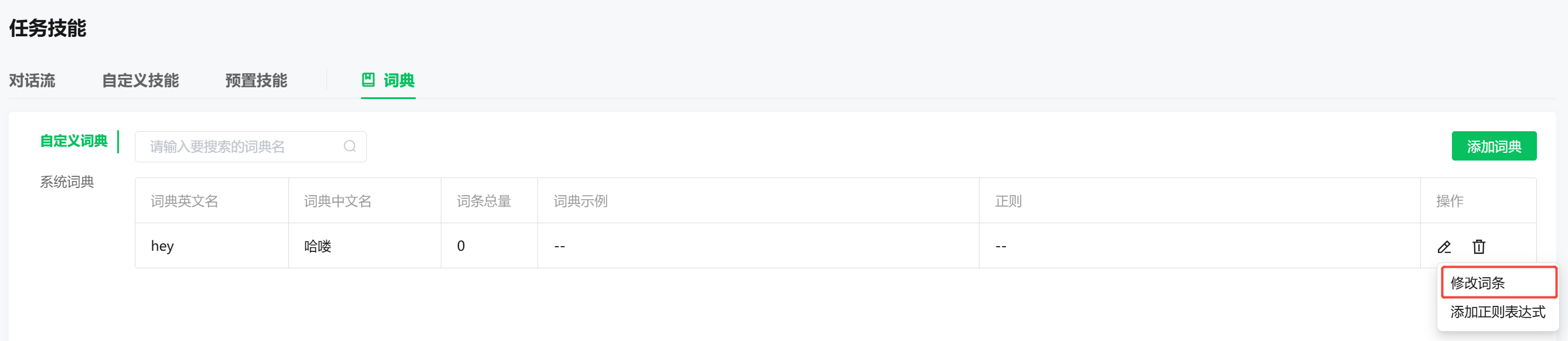
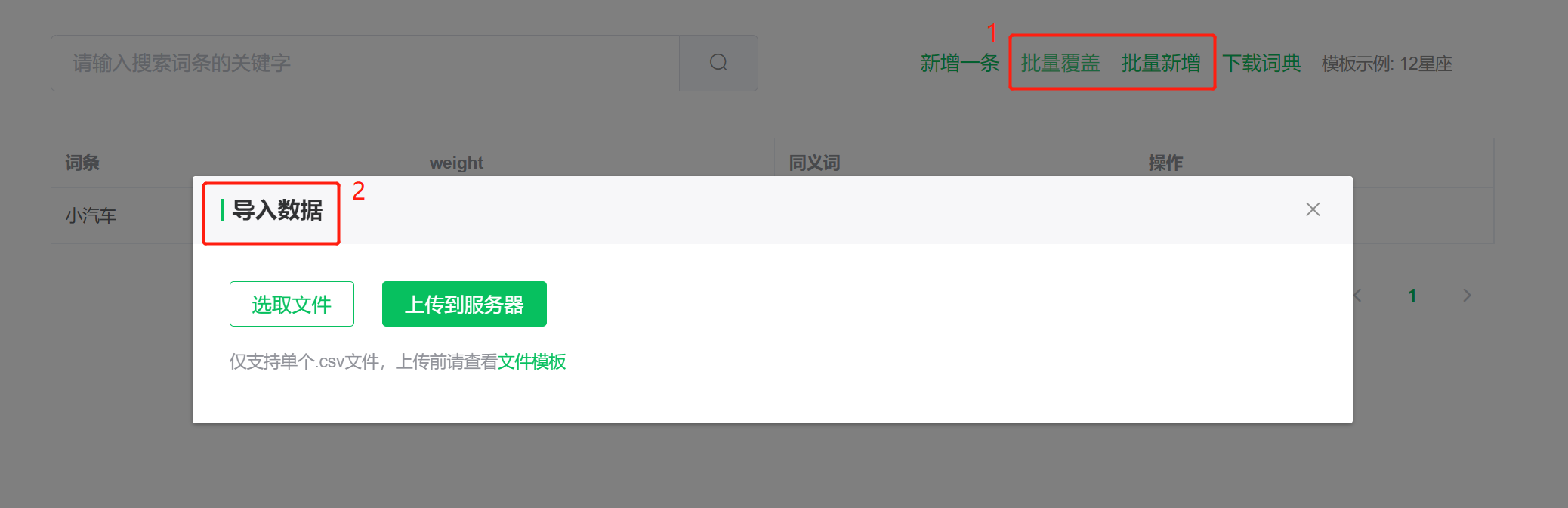
点击【批量新增】或【批量覆盖】选取需要导入数据的文件,点击【上传到服务器】
# 正则词典
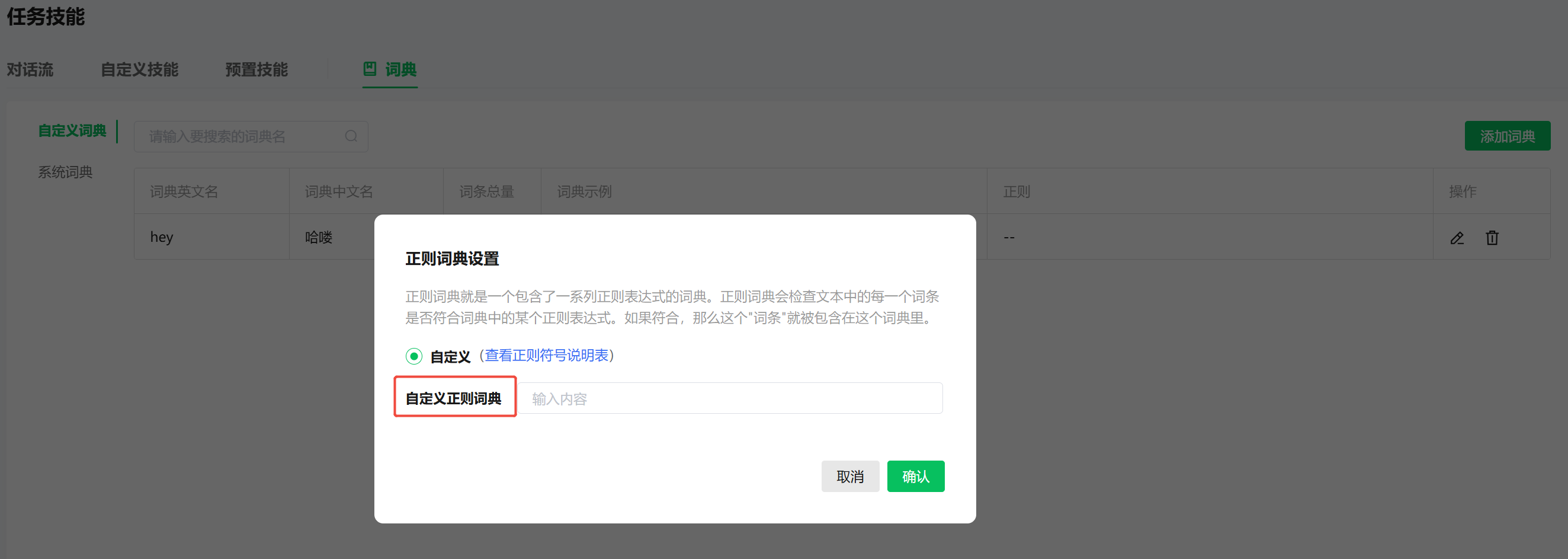
正则词典是基于正则表达式规则进行匹配的词典。正则词典会检查文本中的每一个词条是否符合词典中的某个正则表达式。如果符合,那么这个"词条"就被包含在这个词典里。
# 1. 正则表达式
支持所有标准和扩展正则表达式规范,用户配置时按照正则表达式规范进行配置即可。
# 2. 标准正则表达式
标准正则表达式又称基本正则表达式,是最早指定的正则表达式规范。
表达式字符
基本正则表达式字符及其含义如下表所示。
| 字符 | 含义 |
|---|---|
| "^" | 匹配字符串的开头。如 "^"word,搜索以 word 开头的内容 |
| $ | 匹配字符串的结尾。如 word$,搜索以 word 结尾的内容 |
| ^$ | 表示空行,不是空格 |
| . | 匹配任意单个字符(不匹配空行) |
| \ | 匹配转义后的字符。如 . 只表示小数点 |
| * | 重复之前的字符或文本 0 个或多个,之前的文本或字符连续 0 次或多次 |
| .* | 匹配任意多个字符 |
| ^.* | 以任意多个字符串开头,.* 尽可能多 |
| [ ] | 匹配集合中的任意单个字符,括号中为一个集合 |
| [x-y] | 匹配连续的字符串范围 |
| [^] | 匹配否定,对括号中的集合取反 |
| {n,m} | 匹配前一个字符重复 n 到 m 次 |
| {n,} | 匹配前一个字符重复至少 n 次 |
| {n} | 匹配前一个字符重复 n 次 |
| () | 将"("与")"之间的内容存储在"保留空间",最大存储 10 个 |
| \n | 通过 \1 至 \10 调用保留空间的内容 |
在正则表达式模式中使用文本字符时,需要注意以下几点:
1、如果使⽤某个特殊字符作为文本字符,需要进行转义。在转义特殊字符时,需要在它前面加上⼀个特殊字符告诉正则表达式将该字符当作普通的文本字符。这个特殊字符就是反斜线""。
因为反斜线""是特殊字符,所以在使用时也需要对其进行转义,因此就会出现两个反斜线的情况。常用的转义字符及其含义如下表所示。
| 转义字符 | 含义 |
|---|---|
| \b | 匹配一个单词边界,指单词和空格间的位置 |
| \B | 匹配非单词边界。如"er\B",可以匹配"verb"中的"er",但不能匹配"never"中的"er" |
| \d | 匹配一个数字字符。它等价于[0-9] |
| \D | 匹配一个非数字字符。它等价于[^0-9] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。它等价于[ \f\n\r\t\v] |
| \S | 匹配任何非空白字符。它等价于[^ \f\n\r\t\v] |
| \w | 匹配包括下划线的任何单词字符,以及数字字符。它等价于[a-zA-Z0-9_] |
| \W | 匹配任何非单词字符。它等价于[^a-zA-Z0-9_] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符。就是转到下一行输出 |
| \r | 匹配一个回车符。回车和换行不同,回车效果是输出回到本行行首 |
| \t | 匹配一个水平制表符。相当于按下键盘的TAB键 |
| \v | 匹配一个垂直制表符。它的作用是让"\v"后面的字符从下一行开始输出,且开始的列数为"\v"前一个字符所在列的后面一列 |
2、脱字符"^"如果出现在行首之外的位置,正则表达式模式将无法进行匹配。在正则表达式模式中如果只使用了脱字符"^",那么就不需要使用转义字符进行转义。
3、"$"字符放在⽂本模式之后来指明数据⾏必须以该文本模式结尾。
4、特殊字符点号(.)用来匹配除换行符之外的任意单个字符。它必须匹配⼀个字符,否则该模式不成立。
5、在字符后面放置星号(*)表明该字符必须在匹配模式的⽂本中出现 0 次或多次。
除了以上的元字符之外,还有由普通字符组成的字符集,可以用来匹配特定类型的字符,如下表字符集及其含义所示。
| 字符集 | 含义 |
|---|---|
[:alnum:] | 匹配任意一个字母或数字,0~9、A~Z 或 a~z |
[:alpha:] | 匹配任意一个字母,a~z 或 A~Z |
[:digit:] | 匹配任意一个数字,0~9 |
[:lower:] | 匹配任意一个小写字母,a~z |
[:upper:] | 匹配任意一个大写字母,A~Z |
[:space:] | 匹配任意一个空白字符,包括空格、制表符、换行符等 |
[:blank:] | 匹配空格和制表符 |
[:graph:] | 匹配任意一个看得见的可打印字符,不包括空白字符 |
[:print:] | 匹配任意一个可以打印的字符,包括空白字符,但是不包括控制字符、EOF文件结束符 |
[:cntrl:] | 匹配任意一个控制字符,即ASCII字符集中的前32个字符,如换行符、制表符等 |
[:punct:] | 匹配任意一个标点符号,如"[]""{}"等 |
[:xdigit:] | 匹配16进制数,即0~9、a~f以及A~F |
# 3.扩展正则表达式
扩展的正则表达式⽀持的元字符比标准的正则表达式要多,但扩展的正则表达式对有些标准正则表达式所⽀持的元字符并不⽀持,下面主要来学习扩展的正则表达式中新增的元字符。
扩展正则表达式字符及其含义如下表所示。
| 字符 | 含义 |
|---|---|
| + | 匹配前一个字符出现一次或多次 |
| ? | 匹配前一个字符出现 0 次或一次 |
| | | 匹配逻辑或者,即匹配"|"前或后的字串 |
| 0 | 匹配正则集合 |
| {n,m} | 等同于基本正则表达式的 {n,m} |
加号(+)类似于星号*。加号表明前面的字符可以出现 1 次或多次,但必须至少出现 1 次。如果该字符没有出现,那么模式就不会匹配。加号也同样适用于字符组,与星号(*)和问号(?)的使用方法相同。
问号(?)表明前面的字符可以出现 0 次或 1 次,它不会匹配多次出现的字符。如果字符组中的字符出现了 0 次或 1 次,模式匹配就成立;但如果两个字符都出现了,或者其中⼀个字符出现了 2 次,模式匹配就不成立。
管道符号(|)表示或者同时过滤多个字符。管道符号在检查数据流时,使用逻辑 or 方式指定正则表达式引擎要用的两个或多个模式。如果任何⼀个模式匹配了数据流文本,文本就通过测试;如果没有模式匹配,则数据流文本匹配失败。
同时管道符号两侧的正则表达式可以采⽤任何正则表达式模式(包括字符组)来定义文本。
正则表达式模式也可以使用圆括号进行分组。当将正则表达式模式进行分组时,该组会被当作⼀个标准字符。可以像对普通字符⼀样给该组使用特殊字符。
扩展正则表达式中的花括号可以为重复的正则表达式指定⼀个上限。可以使用以下两种方式来指定区间。
- {n}:正则表达式准确出现 n 次。
- {n,m}:正则表达式至少出现 n 次,至多 m 次。
# 4.正则表达式示例
1、正整数: ^[1-9]\d*$
2、国内身份证号: ^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$
3、国内手机号: ^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
4、国内车牌号: ^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$