# 音频源AudioSource
在游戏场景中可以使用音频源AudioSource播放音频剪辑audioclip。但AudioSource只能播放preloadAudioData=true的audioclip。默认情况下,AudioSource播放的声音直接被AudioListener接收。也可以为AudioSource指定混音器组AudioMixerGroup,使声音先经过混音器AudioMixer实时混音,再流向AudioListener。AudioSource支持以2D、3D或混合(spatialBlend)模式播放,也支持改变声音衰减模式从而改变距离对声音的影响。
# 属性
| 属性 | 功能 |
|---|---|
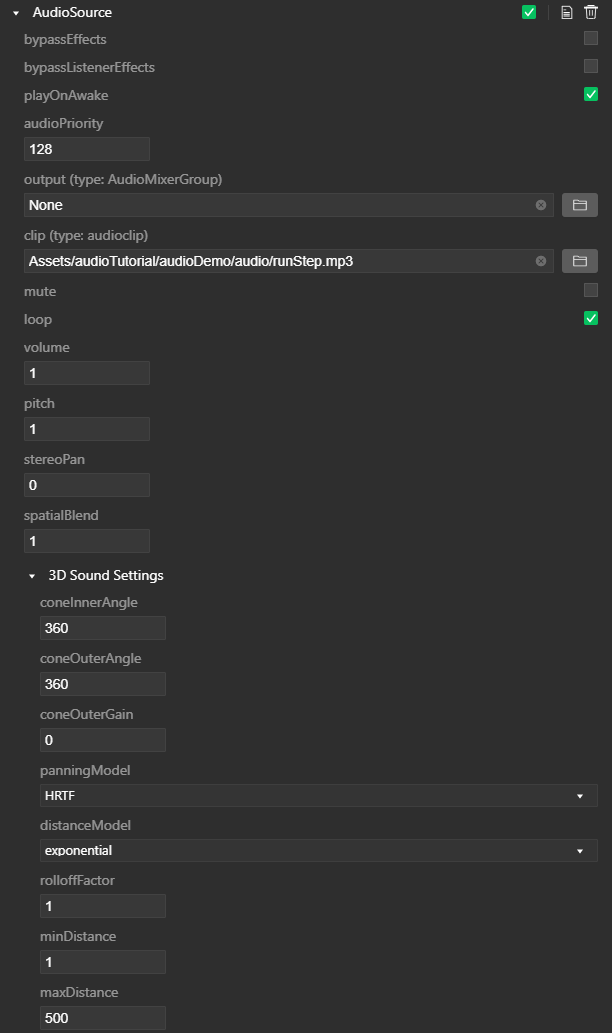
| bypassEffects | 可绕过AudioSource所在节点的所有音效。true:停用音效;false:启用音效。 |
| bypassListenerEffects | 无论AudioSource播放的声音是直接被AudioListener接收,还是先经过AudioMixer处理,再被AudioListener接收,使用此选项均可绕过AudioListener所在节点的所有音效。true:停用音效;false:启用音效。当节点上有且只有一个AudioSource时,bypassListenerEffects=true才有效。即当节点上存在多个AudioSource时,这些AudioSource播放的声音一定会被AudioListener所在节点的所有音效处理。 |
| playOnAwake | 如果启用此选项,声音将在场景启动时自动播放。如果禁用此选项,需要通过脚本调用 AudioSource.play 函数播放声音。 |
| audioPriority | 设置AudioSource播放的声音的优先级。值为0:表示优先级最高。值为255:表示优先级最低。当audioPriority=0时,AudioSource播放的声音不会被设置为虚拟音频,即AudioSource播放的声音一定会被听到。虚拟音频具体策略可参考这里。 |
| output | 默认情况下,声音直接输出到AudioListener。使用此属性可以更改为将声音输出到混音器AudioMixer进行实时混音,然后再输出到AudioListener。 |
| clip | AudioSource将要播放的音频剪辑audioclip。 |
| mute | 启用此选项,则为静音。 |
| loop | 启用此选项,则循环播放。 |
| volume | 设置AudioSource播放的声音的原始音量。注意,此属性值是无单位的。值1:表示音量不变;值0:表示静音。在游戏运行时实际听到的声音音量,除了受该选项影响外,还受到AudioSource与AudioListener之间的距离,或者各种音效、AudioMixer等的影响。 |
| pitch | 声音播放速率。值1:表示正常播放速度。慢速或快速播放会引起音高的变化。 |
| stereoPan | 设置2D声音的左右声道。值-1:只有左声道;值0:双声道;值1:只有右声道 |
| spatialBlend | 设置 3D 空间对音频源的影响程度。值0:只有2D声音,忽略所有3D空间音效的影响;值1:完全3D音效。 |
| coneInnerAngle | 设置声音在播放方向上的圆锥体角度,以度为单位。音频系统使用圆锥体来描述声音的传播方向。在此属性定义的圆锥体内,音量不会降低,即声音不受coneOuterGain属性影响(但是声音还是会受到距离和其他音效的影响)。值360:表示声音向任意方向传播,即在任意方向上均可听到该声音。圆锥体模型可以参考这里。更多信息可参考这里。 |
| coneOuterAngle | 设置声音在播放方向上的圆锥体角度,以度为单位。在此属性定义的圆锥体外,音量将减少到恒定的coneOuterGain属性定义的值。值360:表示声音在任意方向上音量都不会受到coneOuterGain属性影响而减少(但是声音还是会受到距离和其他音效的影响)。更多信息可参考这里。 |
| coneOuterGain | 设置声音在coneOuterAngle属性定义的圆锥体外的音量衰减值。注意,此属性值是无单位的。值1:表示不衰减;值0:表示静音。更多信息可参考这里。 |
| panningModel | 定义计算3D空间音效所使用的算法。更多信息可参考这里。 |
| -- equalpower | 等功率平移空间化算法,简单高效,性能开销较少。 |
| -- HRTF | 质量更高的空间化算法,使用卷积法测量人体受试者的脉冲响应,性能开销较大。 |
| distanceModel | 定义音量随距离变化而变化的算法模型。更多信息可参考这里。 |
| -- inverse | 使用此选项,近距离时音量衰减较大,远距离时音量衰减较小。它适用于以下情况:可以在远距离听到,但当听者非常靠近声源时,音量会显著增加。 |
| -- exponential | 此算法类似于inverse。当rolloffFactor属性值大于1时,音量衰减比inverse衰减快。当rolloffFactor属性值小于1时,音量衰减比inverse衰减慢。当rolloffFactor属性值等于1时,音量衰减和inverse一模一样。 |
| -- linear | 使用此选项,音量将线性衰减,因此当AudioListener接近和远离AudioSource时,音量变化值将保持恒定。此选项适用于不需要严格聚焦3D空间衰减设置的大型背景声音效果之间的淡入淡出。 |
| rolloffFactor | 此属性是distanceModel定义的算法中的一个因子。描述当AudioSource远离AudioListener时,音量衰减的速度。当distanceModel=inverse 或 distanceModel=exponential,rolloffFactor取值范围 [0,∞)。当distanceModel=linear,rolloffFactor取值范围 [0,1]。 更多信息可参考这里。 |
| minDistance | 当AudioSource和AudioListener之间的距离小于该值,音量不因距离而衰减。若距离大于该值,声音开始衰减。更多信息可参考这里。注意:这里的minDistance,代表的是W3C WebAudio PannerNode 的refDistance属性。 |
| maxDistance | 当AudioSource和AudioListener之间的距离大于该值,音量保持不变,不再衰减。更多信息可参考这里。 |
# coneInnerAngle、coneOuterAngle和coneOuterGain
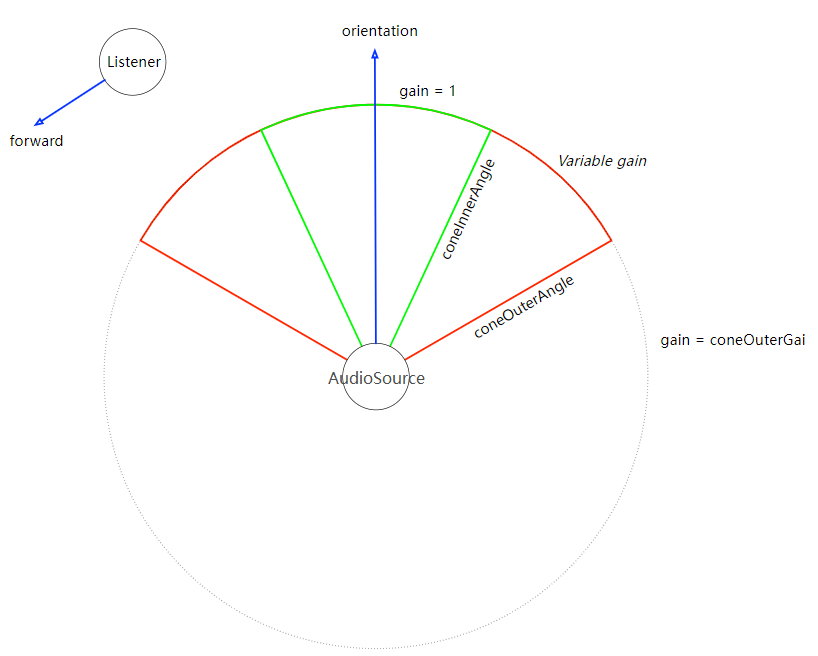
如图orientation表示AudioSource所在entity节点的朝向。绿色区域代表coneInnerAngle形成的圆锥体,其区域内音量gain=1,即不衰减。红色区域代表coneOuterAngle形成的圆锥体。绿色和红色区域之间,音量衰减在coneOuterGain到1之间,为可变衰减。红色区域外音量衰减为恒定的coneOuterGain表示的值。AudioSource的3D音效,除了受coneInnerAngle、coneOuterAngle和coneOuterGain影响外,还会受到距离模型panningModel和其他音效的影响。
# distanceModel距离模型
设 d = AudioSource与AudioListener之间的距离,d1 = minDistance,d2 = maxDistance,f = rolloffFactor,则音量随距离变化而变化的算法模型如下。
| 类型 | 算法描述 |
|---|---|
| inverse | d1 / ( d1 + f * ( max(d, d1) - d1 ) ) 。当d1=0时,算法结果为0。此算法中,f(即rolloffFactor)的取值范围是 [0,∞)。 |
| exponential | Power( max(d, d1) / d1, -f ) ,其中Power是幂函数。当d1=0时,此算法结果为0。此算法中,f(即rolloffFactor)的取值范围是 [0,∞)。 |
| linear | 1 - f * ( max( min(d, d4), d3 ) - d3 ) / ( d4 - d3 ) ,其中 d3 = min(d1, d2),d4 = max(d1, d2)。当d3=d4时,算法结果为 1 - f。此算法中,f(即rolloffFactor)的取值范围是 [0,1]。 |
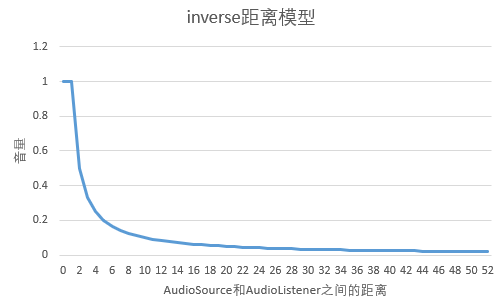
- inverse距离模型图
设minDistance=1,maxDistance=50,f=1,则音量随距离变化而变化的折线图如下:
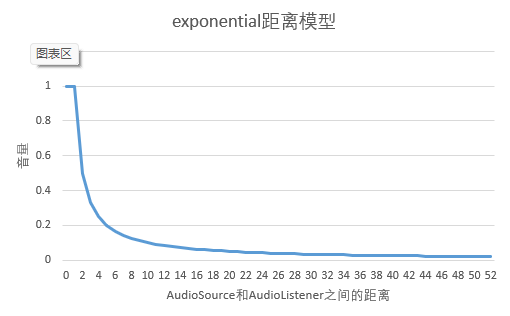
- exponential距离模型图
设minDistance=1,maxDistance=50,f=1,则音量随距离变化而变化的折线图如下:
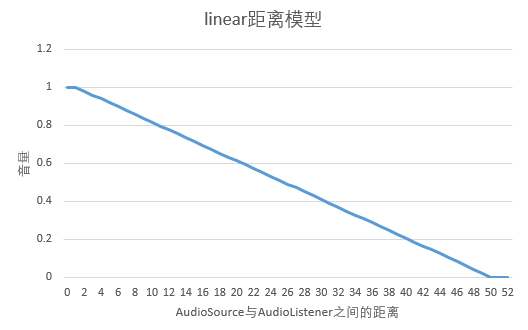
- linear距离模型图
设minDistance=1,maxDistance=50,f=1,则音量随距离变化而变化的折线图如下:
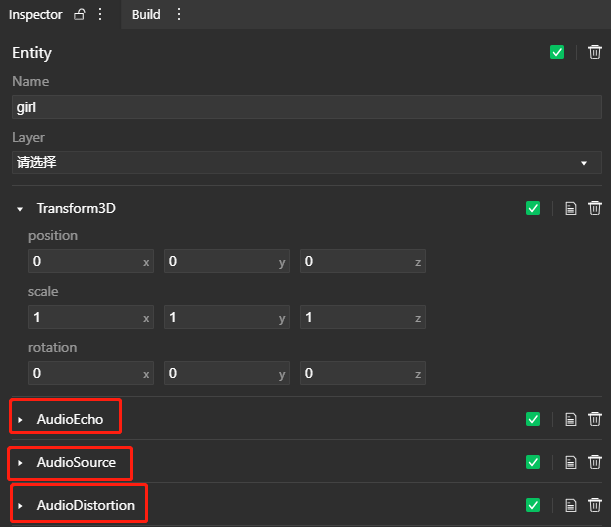
# 音效组件
可以为AudioSource所在的节点添加音效组件,使音效应用于该节点的所有AudioSource。音效组件的顺序很重要。如下图:AudioSource发出的声音,会先经过AudioEcho回声音效处理,再经过AudioDistortion失真音效处理,最后会输出到AudioMixer或AudioListener,具体取决于output属性的配置。
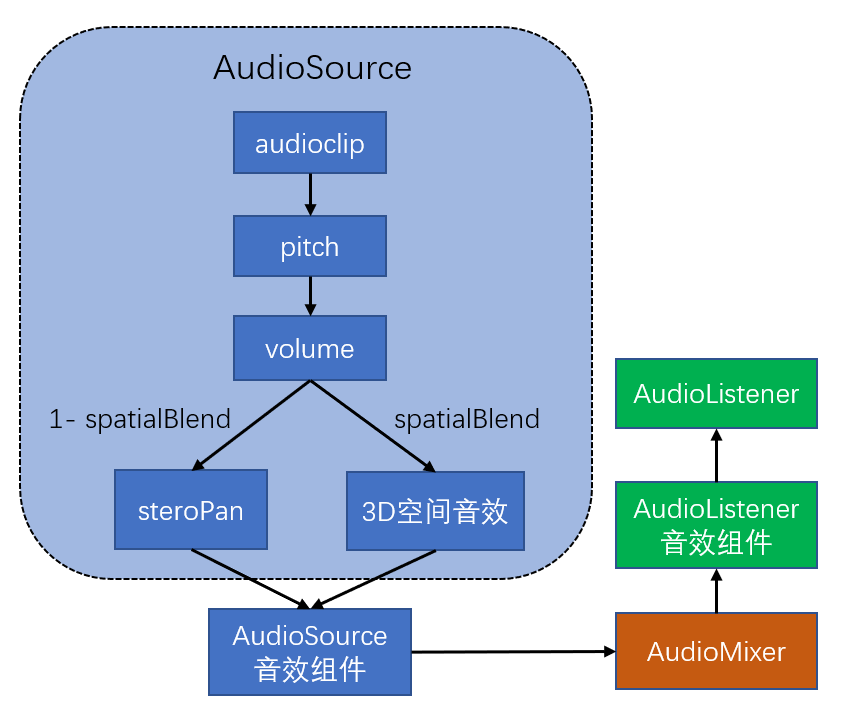
# 声音处理流程
AudioSource播放时,先经过pitch调整播放速率,然后经过volume调整音量大小,接着声音分别路由到steroPan双声道音效和3D空间音效进行处理。注意,steroPan音效和3D空间音效是并行处理的,处理后再进行混合。混合程度取决于spatialBlend的取值。混合后的声音会按顺序路由到AudioSource所在节点的所有音效组件进行处理。最后声音会根据output属性设置,路由到AudioMixer或AudioListener。当然,如果AudioListener所在节点存在音效组件,声音会被音效组件处理后才路由到AudioListener。完整流程图如下:
# 注意
- 默认情况下,节点的朝向是(0, 0, 1)。故为一个新创建的节点添加AudioSource时,声音播放方向为(0, 0, 1)。
- 同一个节点不能同时添加AudioListener和AudioSource,否则可能导致节点上的音效组件工作异常。
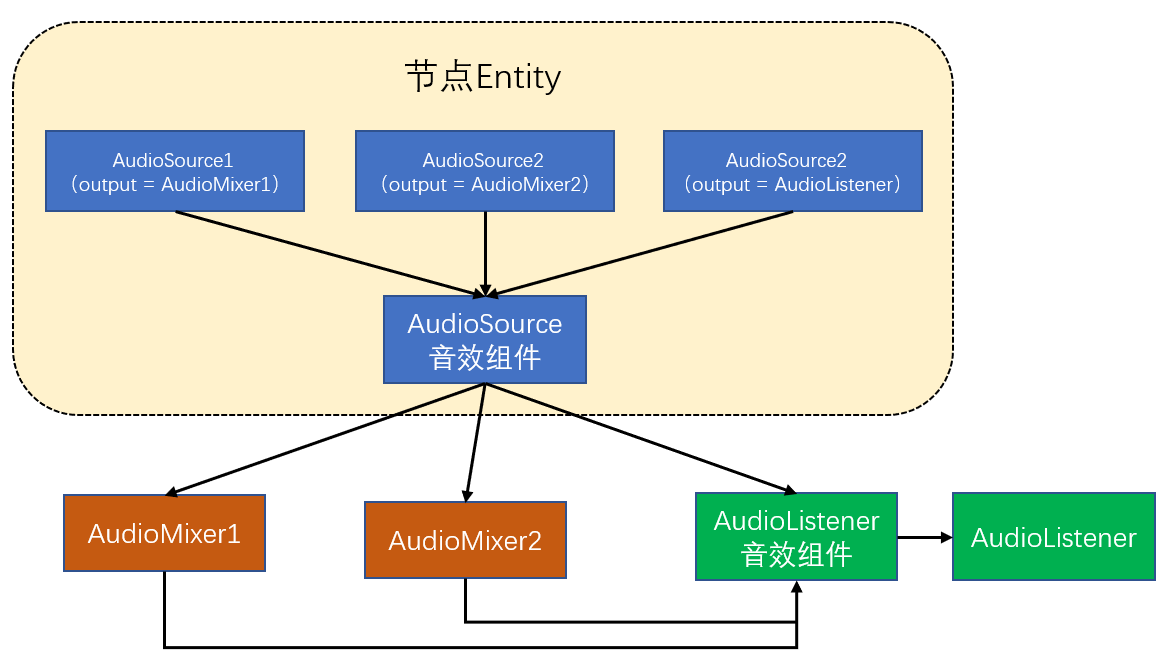
- 绝大部分情况,一个节点只需要添加唯一一个AudioSource。但当一个节点含有多个AudioSource时,此节点上所有的音效组件会共同作用于这些AudioSource。即这些AudioSource发出的声音会在音效组件里混合处理后,再根据AudioSource的output设置,将混合处理后的声音输出到AudioMixer或AudioListener。具体如下图: